As a maintainer of the Flux project, which is part of the CNCF, I was invited to talk at KubeCon 2021 North America.
The talk is on “Flux’s roadmap to General Availability”. It’s a bit sparse, since I was giving an overview. I’ve included some of the illustrations here – for the most part, they were just so people had something to look at that wasn’t my face.
The video recording is on YouTube somewhere in the CNCF channel.
Flux’s roadmap to GA
Today we are going to give you a roadmap for Flux v2 through to general availability (or GA), and a peek beyond.
I’m going to talk about the roadmap, weighted somewhat towards future developments, then Hidde will show you a demo of what you can do with Flux v2 today [this follows in the video].
First of all, who am I? Just some engineer – let’s move on.
How we got here
To summarise the history of Flux:
- What’s now called Flux v1 was created at Weaveworks, to deploy new versions of services to a
software as a service implementation called “Weave Cloud”
- Prior to version Flux v1.0, it concentrated mainly on upgrading container images, but then we made a big change in June 2017 which turned it all around so that it applied everything from git, and made updates by committing to git.
- This was the big bang event for GitOps
- Flux was inducted into the CNCF as a sandbox project in August 2019
- But, by then Flux v1 was creaking ominously; it needed to be modernised. Things like custom resource definitions and controller-runtime weren’t around when it was created!
- In early 2020, what became Flux v2 was started, with the same scope but using modern tooling like controller-runtime, and supporting multiplexing (i.e., more than one sync)
- The Flux project was classified as “Adopt” in the CNCF technology radar in 2020, and was promoted to incubation status in 2021.
Here we are roughly eighteen months after the inception of Flux v2, looking forward to Flux v2 being generally available.
Things that define GA
What does “General Availability” mean? Usually it’s taken to mean that a piece of software is considered ready to run in production. Within open source, people have widely differing appetite for risk, so many have already adopted before a GA release.
Here is what that means for Flux v2. First of all, it means covering the bases that Flux v1 covered, roughly:
- syncing from git to a cluster
- updating image refs in YAML files, and committing to git
- sending notifications (e.g., to Slack) when things have been done
- declarative installation of Helm charts
Most of these things have been generalised in Flux v2; in particular, everything is now multiplexed – you can define as many sources, syncs, updates and notifications as you need.
After a GA release the rule is backward compatibility: public APIs must be stable from this point on. So it’s a point of no return, in that way. There are a few areas that still need development before we’re happy to cross that Rubicon.
End to end testing
To have confidence that Flux does what it says, and that the bug escape rate is under control, we need better coverage in end-to-end tests.
The controllers in Flux have varying unit test coverage. Some things are just hard to test, e.g., notifications to external services. But it’s generally OK.
The command-line tool flux has end-to-end tests, but these are closer to scripts for smoke tests
and coverage of the whole set of controllers together is not great.
One initiative in progress is to rewrite these so that it is possible to permute the inputs and cover a much wider variety of scenarios with all the controllers together.
Controller standardisation
Another area still in development is standardisation. This comes in two parts: a standard for Flux types and controllers, and libraries to help controllers stick to the standard.
The API for Flux goes beyond just the CRDs; there are protocols for how to interoperate with the various objects. For example,
- there’s a protocol for requesting that a resource is processed outside of its specified schedule; this is used by the command-line tool to synchornise with operations it initiates;
- there’s a protocol for discovering and fetching a bundle from a Source object (like a
GitRepositoryorBucket), which other controllers need to understand; - Flux uses
kstatusfor determining whether dependencies are ready, and it is important that its own types are compatible withkstatus; - and, there are standard metrics that Flux dashboards expect controllers to export.
It’s important to have these standards stabilised, and to implement them consistently. That will mean people building on Flux can be sure that their software will interoperate correctly.
Better security model
A big, upcoming addition to Flux is the model for restricting syncs with Kubernetes' role-based access control.
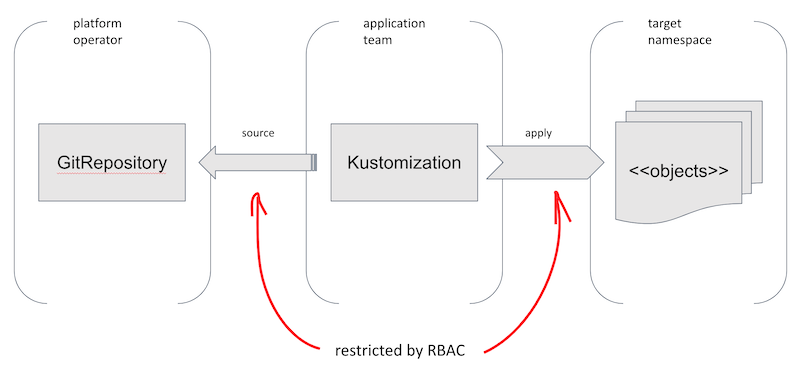
Flux is different from most controllers because by the nature of syncing, it can affect almost anything in the system, including the rules for what it can affect. The proposed security model gives platform operators power to restrict what Flux can do, per namespace or tenant, using Kubernetes RBAC.
This model also enables a scenario which often comes up: you want to separate concerns so that, for example, a platform operator can create a secret giving access to a git repository, and a application team can sync using the git repository without learning the secret.
The picture below shows the general situation: the source, the application, and the target for the application can all have different owners and namespaces, but you still want RBAC to be in effect.
If you know Flux well you might ask: Isn’t this already possible?
Yes, but it is not well enforced. At present, you can give a service account for Flux to use when
syncing; however, the default is to not use a specific service account, which usually means it
will inherit cluster-admin privileges. This is convenient for clusters in which everyone is
trusted, but requires work and extra infrastructure to undo, otherwise.
In the new model, among other things it is possible to default to an unprivileged user, making this aspect secure by default.
New structure for documentation
Another initiative underway is to orient Flux documentation around the different reasons people have for looking at documentation. Sometimes,
- you just want to get something up and running; or,
- you want to learn how it all works; or,
- you need a recipe for some specific task, like setting up on a particular cloud platform; or,
- you’re tweaking a working system, and you need to dive into a reference to find the name of the right option
The aim of reorganising the documentation is to better serve these different entry points, and get people to the most helpful material for them, directly.
Another change coming up for documentation is having specialised sections for the cloud platforms: Azure, GCP, AWS, and so on. It’s useful to collect docs together this way because typically, you are using one of the platforms at a time, and these sections will serve as a one-stop shop for all the relevant information.
The documentation changes are not all pre-requisites for GA, but I wanted to mention them here, because they are nonetheless a part of Flux’s growth and maturity as a project.
Beyond GA
General Availability is merely the end of the beginning. There are more plans afoot – in no particular order:
Using server-side apply instead of kubectl
Flux v1, and Flux v2 have always included kubectl in their container images, as the means of
applying configurations to the Kubernetes API. This is because kubectl contains a lot of logic
that is difficult to reuse or to reproduce, for example doing a three-way merge of a new resource
definition with the current definition and its prior definition.
It is now possible to rely on the Kubernetes API server to do the tricky
bits like merging definitions,
and avoid the need for kubectl. The field management mechanism also lets you see fine-grained
conflicts, which means Flux can be more sophisticated in how it applies configs, and keep out of the
way of other actors like autoscalers.
[NB: this actually made its way into kustomize-controller before KubeCon; I’d recorded the talk a month prior.]
Designs for extensibility
One goal of Flux is to provide primitives for people to build their own GitOps-flavoured continuous delivery. There’s different varieties of that:
- hooking up your system to the inputs and outputs of the controllers in Flux (I would call this “integration”);
- making your own types and controllers that can be used with those in Flux (“extension”)
For the purpose of extension the API is not as open as it could be. By “open” I mean that you don’t need Flux to be changed for you to be able to add to it.
Right now, it is possible to write a controller that consumes sources, but it is not possible to write a controller that provides a new kind of source, because the source types are hard-coded.
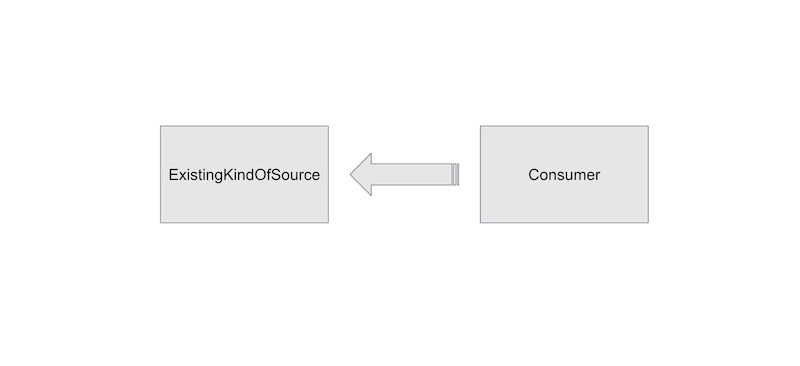
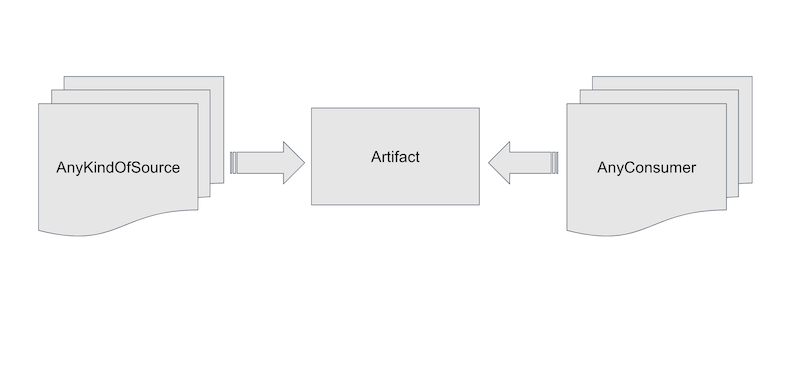
There is a design in progress for removing that limitation by using a type representing the output of a source. This would open the API up to new kinds of source, for example, images and other artifacts from OCI repositories.
Flagger factorisation
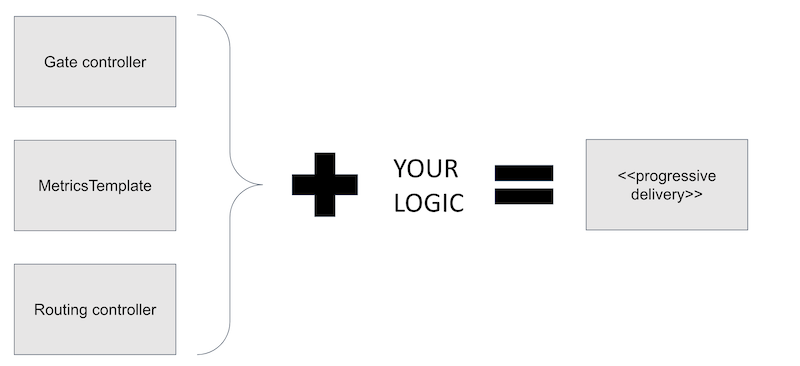
Flagger is now part of the Flux project, but it doesn’t yet use the Flux conventions – it is its own stand-alone thing. It’s also something of a monolith, which does all of:
- creating shadow workload objects so it can route traffic to different versions of a workload;
- controlling the routing of traffic to the different versions;
- evaluating various kinds of gate during a rollout, like running a load test;
- sampling metrics to determine when a rollout can proceed.
Some of these are close to being stand-alone and generic functions, which could be moved into their own API types and controllers. The benefit to doing this is extensibility again: it would easier to build a Flagger analogue that caters to a scenario not in the scope of Flagger.
For example, Flagger deals with workloads (Deployments and DaemonSets), but you might want to roll out another kind of object that doesn’t follow the same rules. You could use the metrics, routing, and gating parts of Flagger, and write your own “shadowing” logic, to have your own form of progressive delivery.
Other kinds of automation
The last thing I want to mention regarding future plans is other kinds of automation.
Flux v2 includes an automation controller which fulfils the same purpose as the “image update” feature of Flux v1. The controller was developed to give some continuity for people who would be migrating from Flux v1; but people have also found it useful in its own right.
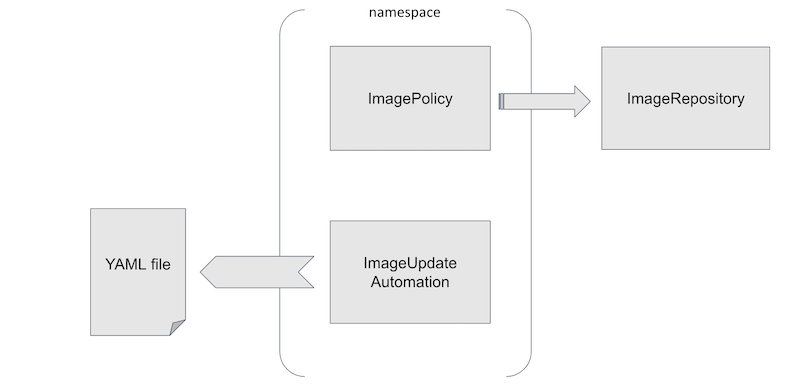
The picture below shows how the bits relate – an ImageRepository scans for an image’s tags, an
ImagePolicy gives a rule for choosing a tag from those, and the ImageUpdateAutomation updates
YAML files according to the policies in its namespace.
The pattern shown for images can be used for other kinds of automation – for example, one kind that
has been requested is updating the chart version of a HelmRelease.
Now to the demo
I have not talked much about what Flux v2 does as of today – I’m now going to hand over to Hidde, who will fill that gap, with a demonstration. [The demonstration is in the video, if you can find that]